Translation / 2026-05-25
Translation Model Benchmark for Multilingual Video Transcripts
This benchmark translated roughly 500,000 characters of real multilingual transcript text from 15 languages into English. It compares Google Translate, DeepL, and Llama Maverick 4 across quality, latency, reliability, and practical operating tradeoffs.
Sampled from a production transcript table
Top non-English languages by transcript volume
COMET-QE -0.4481, 10 of 15 language wins
851 ms average latency
Choose a production-ready translation path for noisy multilingual ASR transcript text without relying on clean benchmark corpora.
Translated 293 transcript segments across 15 languages and compared quality, latency, reliability, throughput, and length behavior across three providers.
Llama produced the best COMET-QE quality and reliability, while DeepL was the strongest low-latency option for real-time paths.
- Python
- Google Translate
- DeepL
- Llama Maverick 4
- Together AI
- COMET-QE
- BLEU
- BERTScore
Context
The test used ASR-style video transcripts rather than clean written text, which makes the benchmark closer to production transcript translation. The source table contained 84 million total transcripts, and the sampled workload covered about 33,333 characters per language.
The compared systems were Google Translate through the unofficial googletrans library, DeepL through the official API, and Meta Llama 4 Maverick 17B-128E through Together AI.
At a glance
| Dimension | Winner | Why |
|---|---|---|
| Translation quality | Llama Maverick 4 | Highest overall COMET-QE score and strongest language coverage. |
| Speed | DeepL | About 7x faster than Llama and about 1.5x faster than Google. |
| Reliability | Llama Maverick 4 | One timeout across 293 segments. |
| Free-tier cost | Tie | All systems were free for this roughly 500k character benchmark volume. |
Overall results
All attempted translations
| Model | Success | Error rate | Avg latency | Throughput | COMET-QE | Length ratio |
|---|---|---|---|---|---|---|
| 241/293 | 17.7% | 1,299 ms | 477 chars/s | -0.4813 | 1.253 | |
| DeepL | 279/293 | 4.8% | 851 ms | 1,341 chars/s | -0.4863 | 1.248 |
| Llama | 292/293 | 0.3% | 6,088 ms | 201 chars/s | -0.4481 | 1.641 |
Fair comparison excluding integration failures
| Model | Success | Error rate | Avg latency | Throughput | COMET-QE | Length ratio |
|---|---|---|---|---|---|---|
| 241/241 | 0.0% | 1,299 ms | 477 chars/s | -0.4813 | 1.253 | |
| DeepL | 279/279 | 0.0% | 851 ms | 1,341 chars/s | -0.4863 | 1.248 |
| Llama | 292/293 | 0.3% | 6,088 ms | 201 chars/s | -0.4481 | 1.641 |
Language-level findings
Llama won 10 of the 15 languages by COMET-QE, while Google won five. DeepL was rarely the quality winner in this transcript-heavy sample, but it remained the strongest option when latency mattered.
| Language | Google COMET | DeepL COMET | Llama COMET | Winner |
|---|---|---|---|---|
| Spanish | -0.4340 | -0.4439 | -0.4017 | Llama |
| Portuguese | -0.5881 | No data | -0.5871 | Llama |
| Russian | -0.3498 | -0.4469 | -0.3611 | |
| Japanese | -0.6601 | -0.6506 | -0.5692 | Llama |
| Hindi | -0.3107 | -0.3489 | -0.2503 | Llama |
| French | -0.7363 | -0.6186 | -0.5516 | Llama |
| German | -0.1751 | -0.2135 | -0.2205 | |
| Chinese | No data | -0.3471 | -0.1618 | Llama |
Recommendation
- Use Llama Maverick 4 when quality is the primary goal and batch latency is acceptable.
- Use DeepL for real-time or high-volume product paths where sub-second latency matters.
- Use Google through the official API, not googletrans, for cost-sensitive batch processing where moderate reliability and quality are acceptable.
- Run a follow-up benchmark on low-resource languages because the current sample focused on common languages only.
Detailed methodology and results
Supporting methodology, figures, and tables are rendered here as native page content with the same visual system as the rest of this website.
Comparing Google Translate, DeepL, and Llama Maverick 4 across 15 languages
Generated from ~500,000 characters of video transcript data (293 segments)
Executive Summary
The benchmark compares three translation services by translating ~500,000 characters of real video transcript data from 15 languages into English. The corpus uses Iceberg-backed automatic speech recognition (ASR) transcript data - making this a realistic test of how these models handle noisy, informal, spoken-language content.
Key finding: Llama Maverick 4 produced the highest-quality translations (COMET-QE: -0.4481) with near-perfect reliability (99.7% success rate), winning 10 out of 15 languages. DeepL was the fastest (avg 851ms, median ~635ms) and most cost-efficient for real-time use. Google Translate was competitive on quality - winning 5 out of 15 languages - but suffered from reliability issues due to the unofficial API library used.
At a glance
| Category | Winner | Details |
|---|---|---|
| Translation Quality | Llama | Highest COMET-QE score across most languages |
| Speed | DeepL | ~7x faster than Llama, ~1.5x faster than Google |
| Reliability | Llama | Only 1 failure out of 293 segments (timeout on long text) |
| Cost (free tier) | All tied | All three were free for this volume (~500K chars) |
Methodology
This benchmark was designed to evaluate translation quality on real-world, messy content rather than curated test sets.
Data source
- Source: large Iceberg-backed transcript table (84M total transcripts)
- Selection: Top 15 non-English languages by volume, ~33,333 characters per language
- Content type: ASR video transcripts - informal, spoken language with typical ASR noise
- Total: 293 segments, ~500,000 characters
Models tested
- Google Translate - via googletrans library (unofficial free API)
- DeepL - via official DeepL API (free tier, 500K char/month)
- Llama Maverick 4 - Meta's Llama 4 Maverick 17B-128E via Together AI API
Metrics
- COMET-QE - Reference-free translation quality score (Unbabel/wmt20-comet-qe-da). Higher is better. Does not need human reference translations.
- Latency - Wall-clock time per API call in milliseconds
- Throughput - Characters translated per second
- Length ratio - Ratio of translation length to source length (1.0 = same length)
- Error rate - Percentage of segments that failed to translate
- Cross-model BLEU/chrF/BERTScore - Pairwise similarity between translations from different providers
Note on COMET-QE scores: The wmt20-comet-qe-da model outputs scores that can be negative. These are relative quality indicators - what matters is the comparison between providers, not the absolute values. Negative scores are expected for ASR transcripts which are inherently noisy.
Results - All Data (Including Errors)
This section shows the raw results from all 293 segments sent to each provider. Some errors were caused by benchmark integration issues, not by the translation services themselves. Those cases are separated in the error analysis below.
| Provider | Success | Error Rate | Avg Latency (ms) | Avg Throughput (chars/s) | COMET-QE | Length Ratio |
|---|---|---|---|---|---|---|
| 241/293 | 17.7% | 1299 | 477 | -0.4813 | 1.253 | |
| Deepl | 279/293 | 4.8% | 851 | 1341 | -0.4863 | 1.248 |
| Llama | 292/293 | 0.3% | 6088 | 201 | -0.4481 | 1.641 |
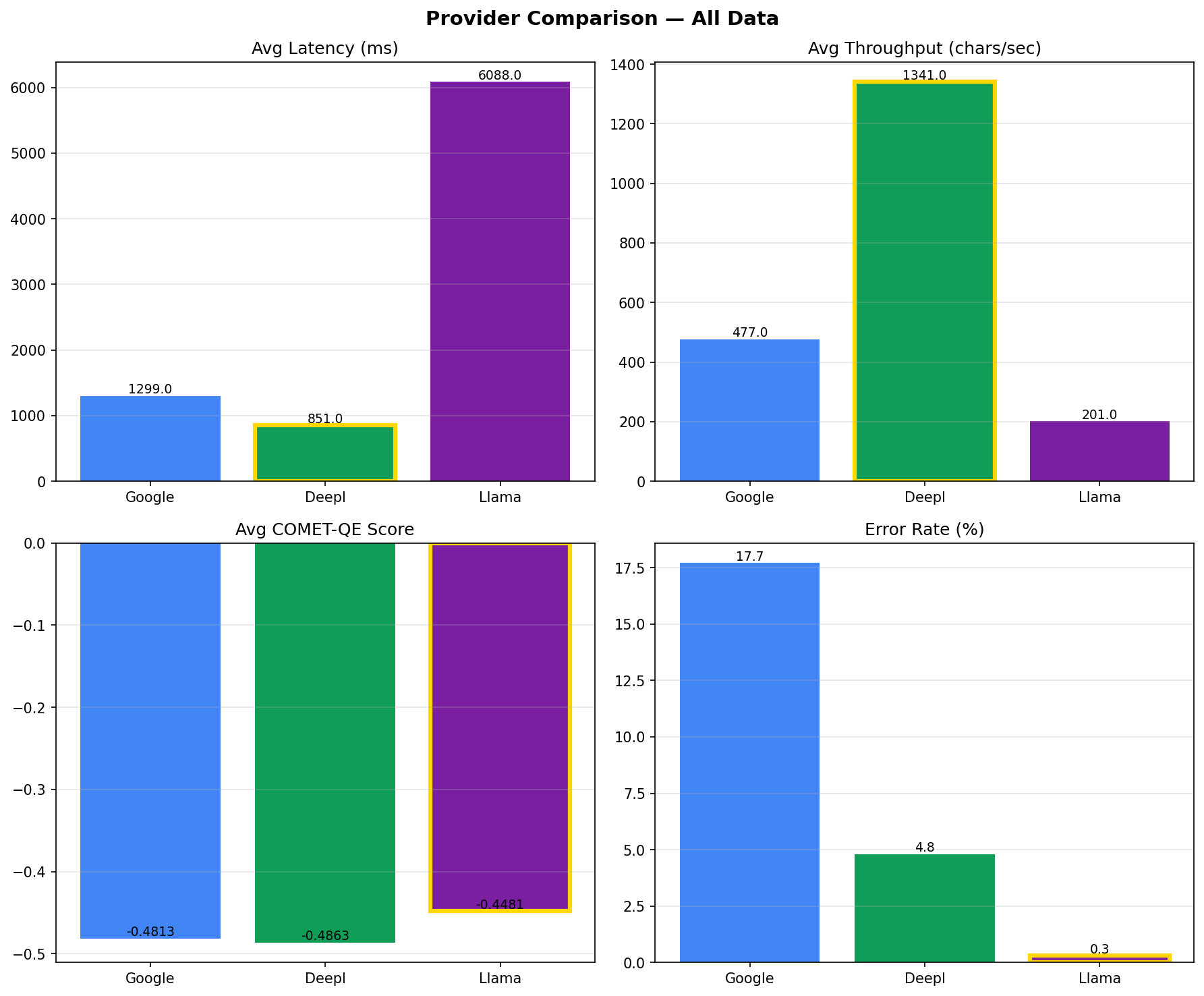
The four bar charts above compare average latency, throughput, COMET-QE quality, and error rate. Gold borders highlight the best performer in each category. Llama leads on quality (COMET-QE: -0.4481) and error rate (0.3%). DeepL leads on speed (851ms avg, 1341 chars/sec). Note that Google's 17.7% error rate and DeepL's 14 Portuguese failures are caused by integration issues, not translation quality issues.
Error Analysis
Out of 879 total translation attempts (293 segments x 3 providers), 67 failed. The vast majority were caused by issues in the benchmark harness, not by the translation services.
| Provider | Error Type | Count | Root Cause | Integration Issue? |
|---|---|---|---|---|
| Invalid source language | 18 | The harness sent zh but googletrans requires zh-cn | Yes | |
| JSON parse error / rate limit | 34 | The unofficial googletrans library was rate-limited by Google's anti-bot protection | Partial - library choice | |
| DeepL | Unsupported source_lang | 14 | The harness sent PT-BR as source language - valid only as target in DeepL API | Yes |
| Llama | Read timeout | 1 | A 15,028-char Korean segment exceeded the 120s timeout | Partial - timeout too low |
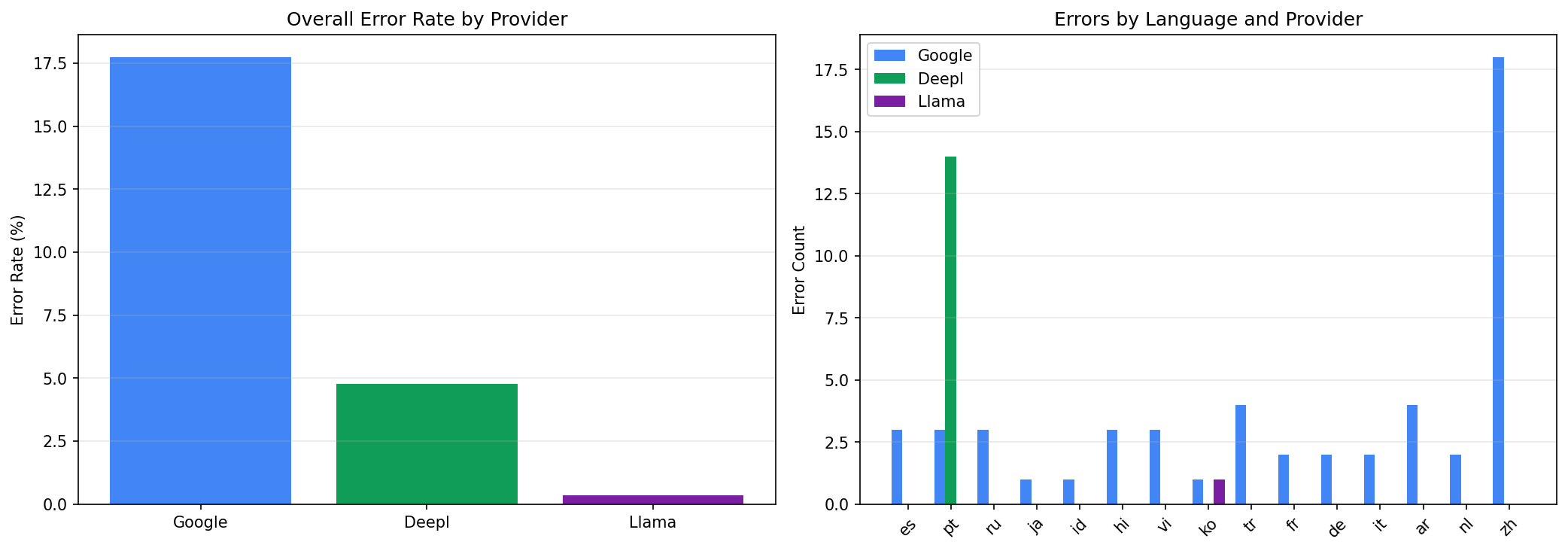
The left chart shows overall error rates: Google at 17.7%, DeepL at 4.8%, and Llama at just 0.3%. The right chart breaks down errors by language - notice that Google's 18 Chinese errors (code bug sending wrong language code) and 34 errors spread across other languages (rate limiting from the unofficial library), while DeepL's 14 errors are concentrated entirely in Portuguese (a source-language mapping issue). These patterns confirm the errors are not quality-related.
Impact on results: To ensure a fair comparison, the next section excludes all 52 Google error segments (since the unofficial googletrans library is responsible for all failures - both the Chinese language code bug and rate limiting) and all 14 DeepL Portuguese segments (a source-language mapping issue). This gives each provider a level playing field, with only Llama's single timeout remaining as a genuine operational failure.
Results - Fair Comparison (Excluding Integration Issues)
This comparison removes all 52 Google error segments - both the Chinese language code bug (18) and rate limiting (34) are caused by using the unofficial googletrans library - and all 14 DeepL Portuguese segments affected by a source-language mapping issue. After exclusion, Google and DeepL both show 0% error rate, with only Llama's single timeout (0.3%) remaining.
| Provider | Success | Error Rate | Avg Latency (ms) | Avg Throughput (chars/s) | COMET-QE | Length Ratio |
|---|---|---|---|---|---|---|
| 241/241 | 0.0% | 1299 | 477 | -0.4813 | 1.253 | |
| Deepl | 279/279 | 0.0% | 851 | 1341 | -0.4863 | 1.248 |
| Llama | 292/293 | 0.3% | 6088 | 201 | -0.4481 | 1.641 |
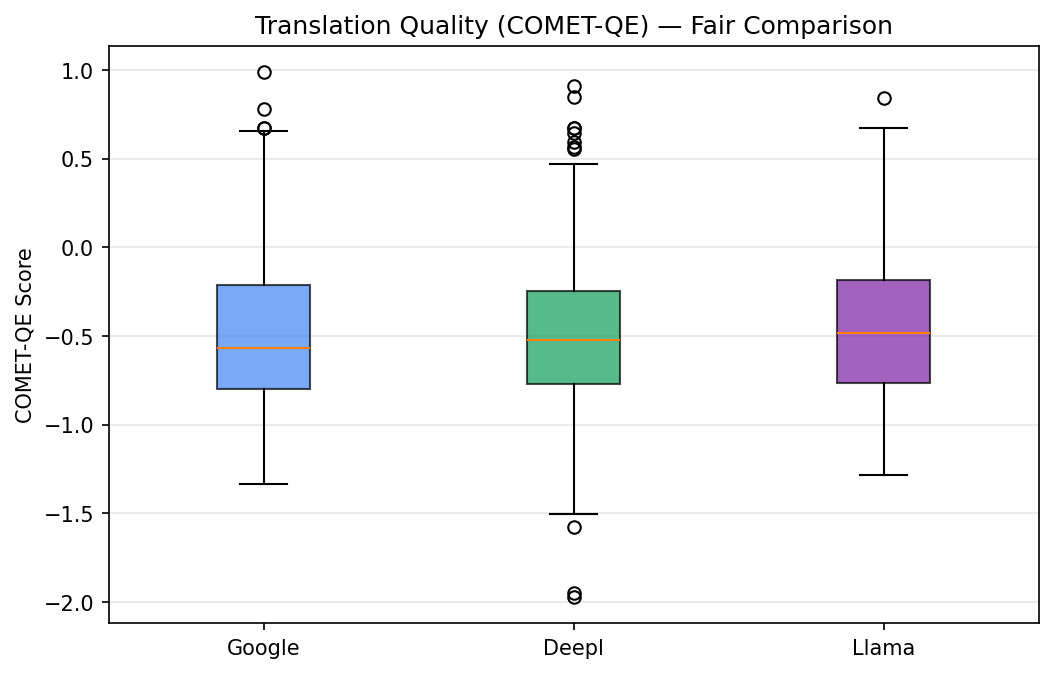
Left chart (Quality): COMET-QE score distribution per provider. The box shows the middle 50% of scores, with the line inside marking the median. Llama Maverick 4 has the highest median (-0.4481 avg) and the tightest spread, meaning it produces consistently good translations. Google (-0.4813 avg) and DeepL (-0.4863 avg) are very close to each other but both trail Llama.
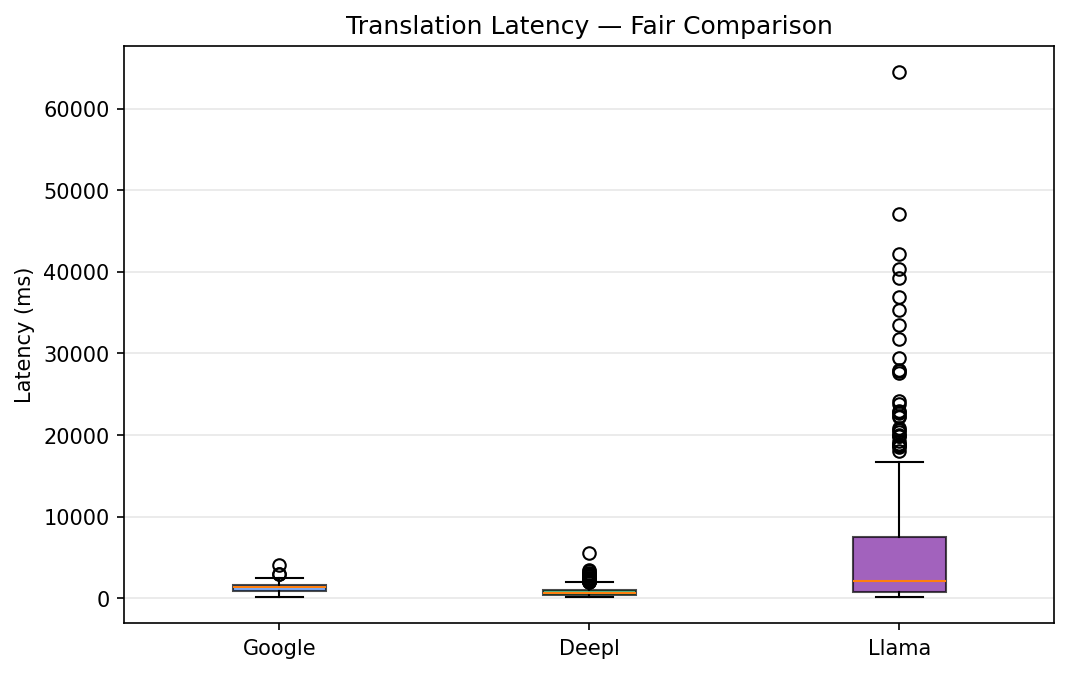
Right chart (Speed): Latency distribution per provider. DeepL is clearly the fastest - its box is tightly clustered with a median around 635ms. Google sits in the middle at ~1,300ms average. Llama is significantly slower with an average of ~6,088ms and a long upper tail, with some segments exceeding 60 seconds for very long texts. This is the trade-off for running a large language model per translation request.
Translation Quality Deep Dive
COMET-QE (Quality Estimation) evaluates translations without needing human references. It uses a trained neural model to assess how well the translation captures the meaning of the source text.
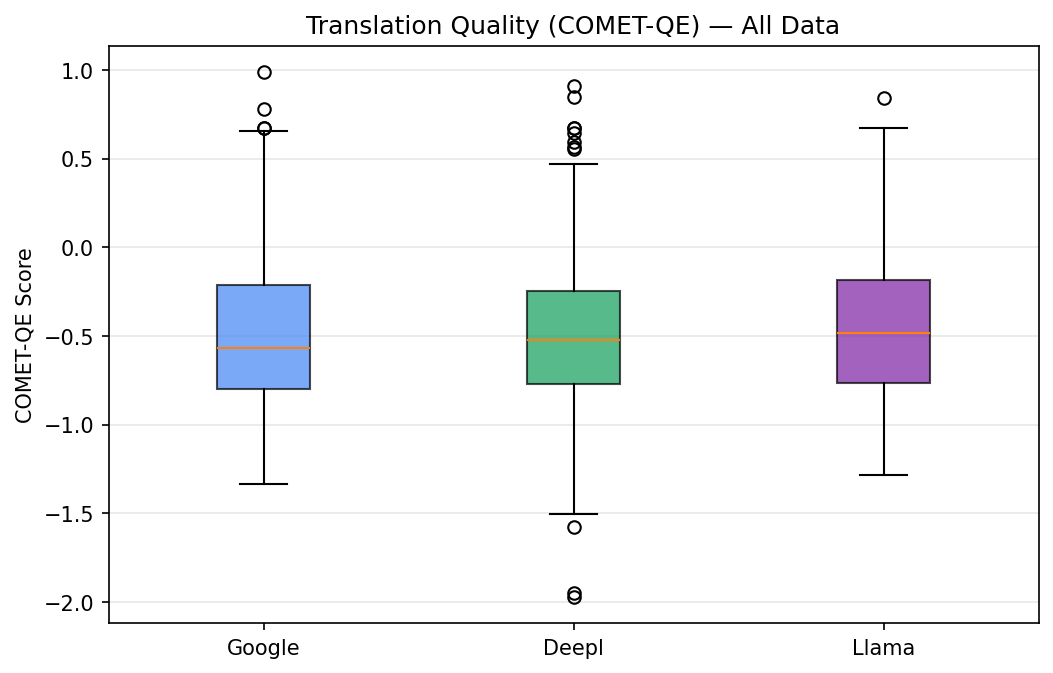
Left chart (COMET-QE - All Data): Quality distribution across all successful translations. Each box shows the middle 50% of scores with the median line inside. Llama's median (-0.4481 avg) is noticeably higher than Google (-0.4813) and DeepL (-0.4863), and its box is narrower - meaning it produces more consistently good translations with fewer low-quality outliers.
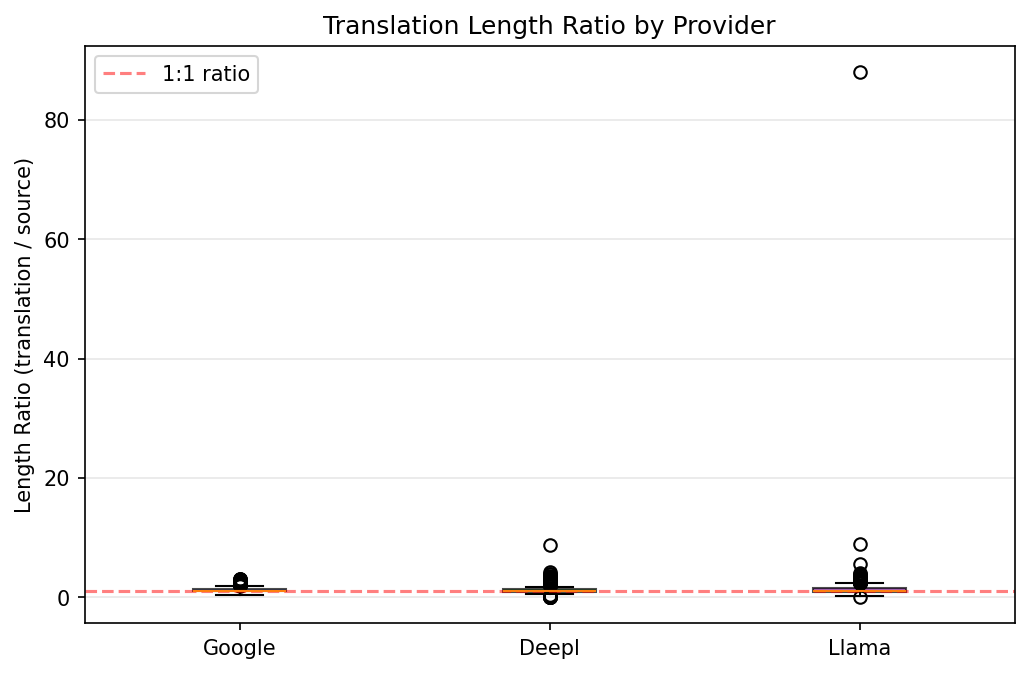
Right chart (Length Ratio): How long are the translations compared to the source text? A ratio of 1.0 (the red dashed line) means the translation is exactly the same length as the source. Google (1.253 avg) and DeepL (1.248 avg) produce translations roughly 25% longer than the source - typical when translating from compact languages like Chinese, Japanese, and Korean into English. Llama (1.641 avg) produces translations ~64% longer - it tends to be more verbose, sometimes adding context or rephrasing more extensively. Note the wide spread in all boxes: length ratio varies significantly by source language.
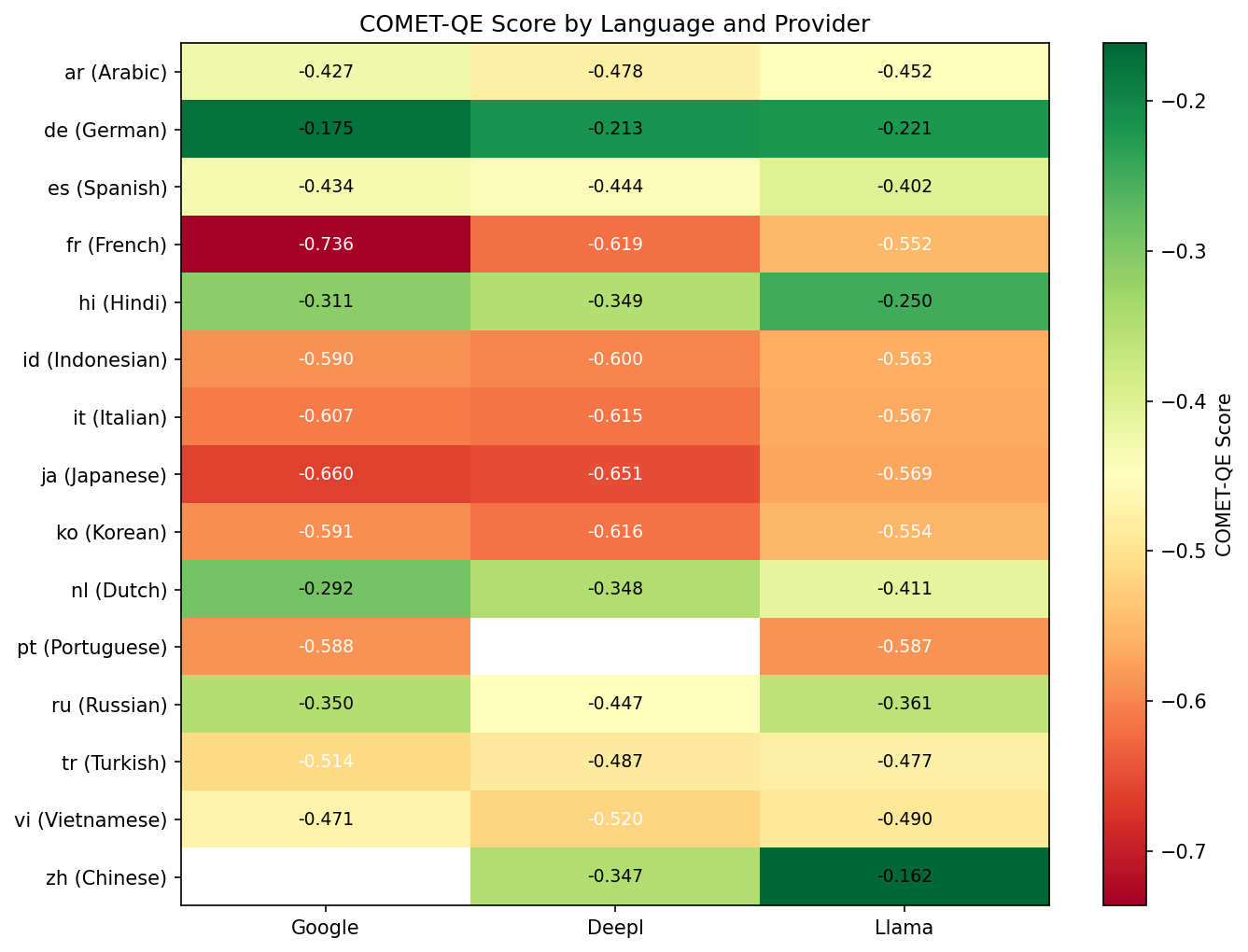
This heatmap shows COMET-QE quality broken down by language (rows) and provider (columns). Each cell contains the average score for that combination. Green cells indicate higher quality; red/yellow cells indicate lower quality. Key observations:
- Llama wins 10 out of 15 languages - it is the best provider for Spanish, French, Hindi, Indonesian, Italian, Japanese, Korean, Portuguese, Turkish, and Chinese
- Google wins 5 languages - Arabic, German, Dutch, Russian, and Vietnamese, where it slightly edges out the competition
- European languages (German, Dutch, Russian) tend to score higher across all providers - these are well-resourced languages with clean ASR output
- Asian languages (Japanese, Korean) and Indonesian show lower scores across the board, likely reflecting noisier ASR transcripts and harder translation pairs
- Missing cells (e.g., Google for Chinese) indicate where a provider had no successful translations due to benchmark integration issues
Cross-Model Agreement
Beyond evaluating each provider individually, the benchmark measured how much the three providers agree with each other . When two independent translation systems produce similar output for the same input, it increases confidence that both are correct. The benchmark used three pairwise metrics:
- BLEU - Measures word-level overlap between two translations (0 - 100). Higher means more similar phrasing.
- chrF - Character-level overlap, less sensitive to exact word choice (0 - 100). Good for morphologically rich languages.
- BERTScore F1 - Semantic similarity using neural embeddings (0 - 1). Two translations can score high even if they use completely different words, as long as the meaning is the same.
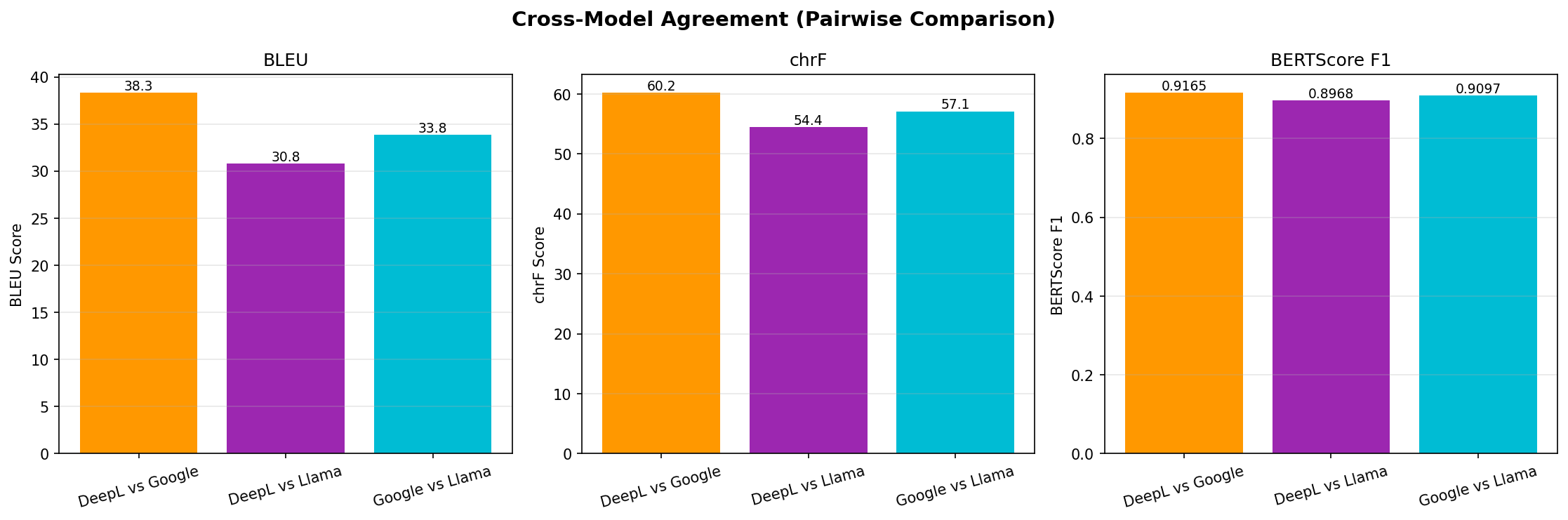
The three panels above show average pairwise BLEU, chrF, and BERTScore F1 for each provider pair. Each bar represents the average agreement between two providers across all segments where both succeeded. Key takeaways:
- DeepL and Google agree the most - BLEU 38.3, chrF 60.2, BERTScore 0.917. Both are dedicated translation engines optimized for fluent, concise output, so they tend to produce similar phrasing.
- Google and Llama show moderate agreement - BLEU 33.8, chrF 57.1, BERTScore 0.910. Despite Llama's different approach (LLM vs translation engine), it often converges on similar output to Google.
- DeepL and Llama diverge the most - BLEU 30.8, chrF 54.4, BERTScore 0.897. Llama's higher length ratio (1.64x) means it rephrases more freely, producing longer translations that lower word-level overlap even when meaning is preserved.
- BERTScore F1 is high across all pairs (0.897 - 0.917), confirming that despite surface-level wording differences, all three providers capture the same core meaning. The translations are semantically equivalent.
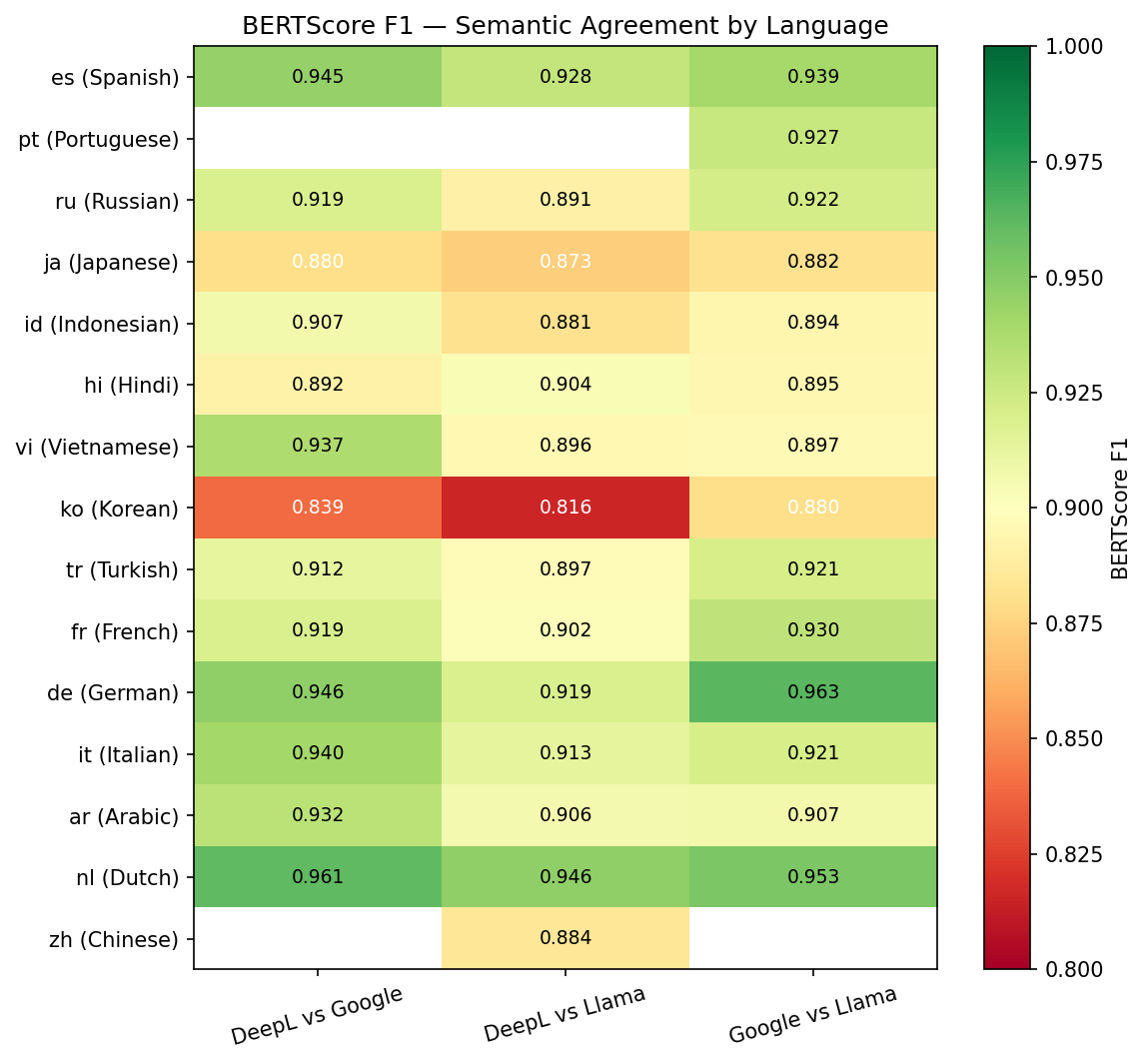
This heatmap breaks down BERTScore F1 by language (rows) and provider pair (columns). Each cell shows the average semantic similarity between two providers' translations for that language. Greener cells = higher agreement, yellower cells = more divergence. Key patterns:
- European languages (Spanish, French, German, Italian, Dutch) show the highest cross-model agreement - all providers translate these well and produce semantically similar output.
- Asian languages (Japanese, Korean, Chinese) and Arabic show slightly lower agreement, reflecting genuine differences in how each model handles more distant language pairs with different scripts and grammar.
- DeepL vs Google (left column) is consistently the greenest - these two dedicated translation engines agree the most across all languages.
- Overall, the uniformly green heatmap (values mostly above 0.88) confirms that all three providers produce semantically equivalent translations across all 15 languages tested.
Speed Throughput
For production use, translation speed matters - especially for real-time applications or high-volume batch processing.
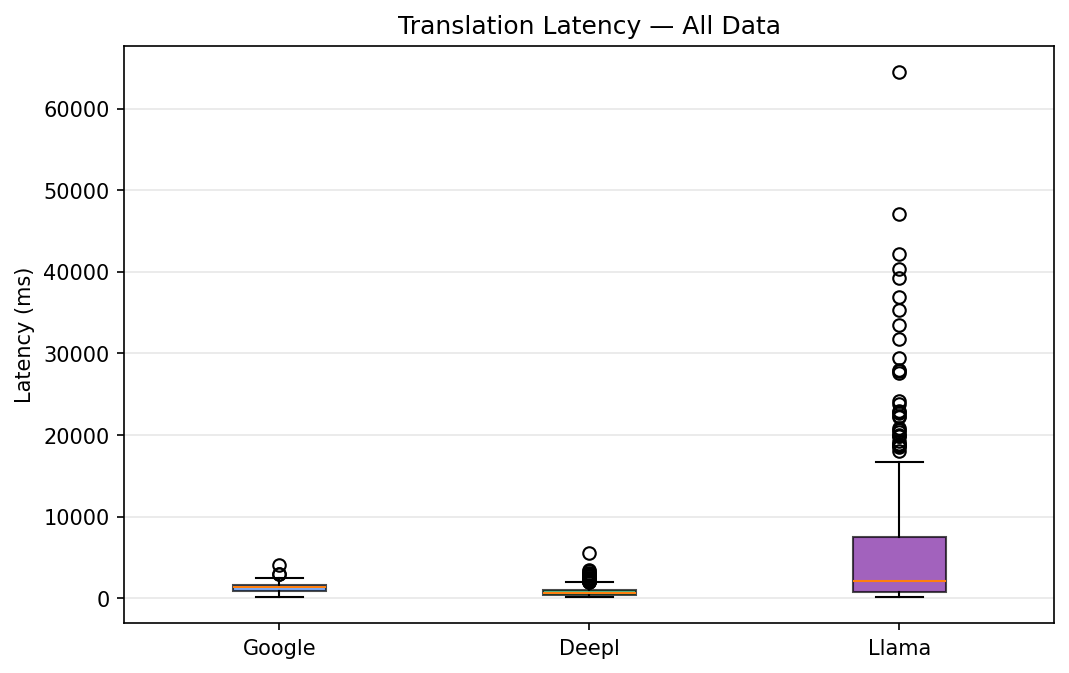
Left chart (Latency - All Data): Box plots showing response time per provider. DeepL consistently responds under 2 seconds (median ~635ms, max ~5.6s). Google averages ~1,299ms with moderate variance (range 131 - 4,108ms). Llama averages ~6,088ms with an extremely long tail - while the median is ~2,072ms, the worst case reached 64 seconds for a long Korean segment.
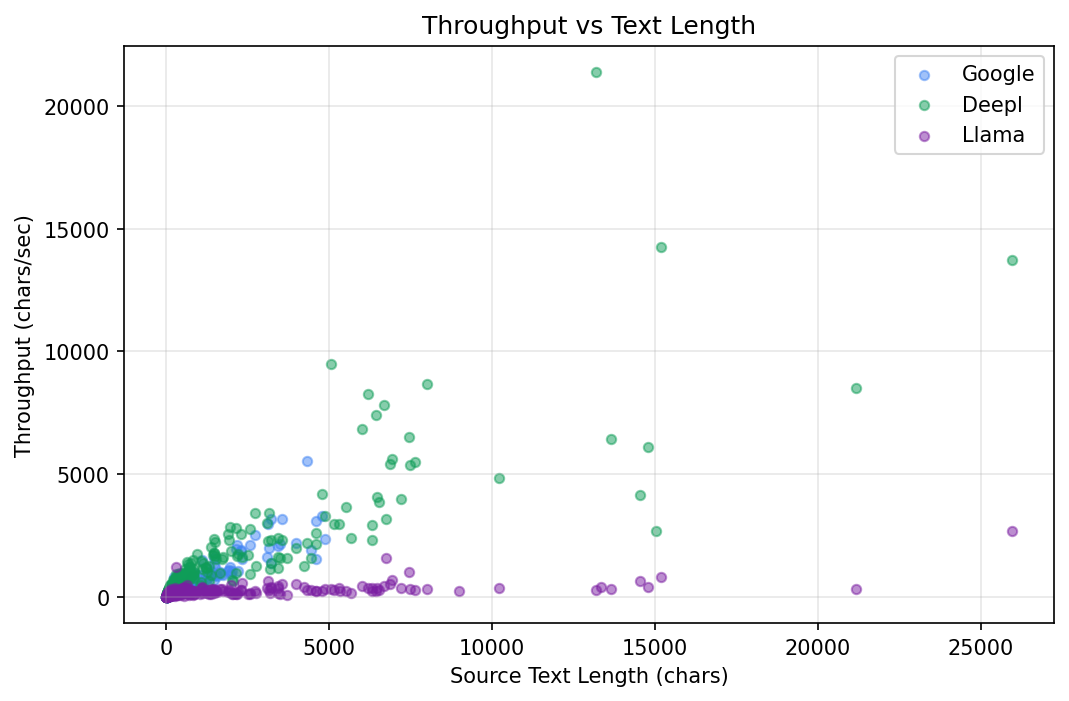
Right chart (Throughput vs Text Length): Each dot represents one translated segment, plotting source text length (x-axis) against characters processed per second (y-axis). DeepL (green, top) maintains the highest throughput (~1341 chars/sec avg) regardless of text size, with some large segments exceeding 5,000 chars/sec. Google (blue, middle) averages ~477 chars/sec. Llama (purple, bottom) processes at ~201 chars/sec - the cost of running each segment through a full LLM inference pass.
Speed takeaway: If the use case requires real-time translation (e.g., live subtitles, chat), DeepL is the clear choice at ~1341 chars/sec. For batch processing where quality matters more than speed, Llama's ~201 chars/sec is acceptable.
Per-Language Breakdown
This table shows COMET-QE quality scores and average latency for each of the 15 languages tested, broken down by provider. Each cell shows the quality score (top) and the average latency plus segment count (bottom). Only successful translations are included - blank cells mean the provider failed all segments for that language.
| Language | Google COMET-QE / Latency | DeepL COMET-QE / Latency | Llama COMET-QE / Latency |
|---|---|---|---|
| es (Spanish) | -0.4340 882ms - 15 seg | -0.4439 643ms - 18 seg | -0.4017 7079ms - 18 seg |
| pt (Portuguese) | -0.5881 917ms - 11 seg | No data | -0.5871 8730ms - 14 seg |
| ru (Russian) | -0.3498 1118ms - 10 seg | -0.4469 598ms - 13 seg | -0.3611 8950ms - 13 seg |
| ja (Japanese) | -0.6601 1055ms - 17 seg | -0.6506 962ms - 18 seg | -0.5692 9092ms - 18 seg |
| id (Indonesian) | -0.5898 1249ms - 24 seg | -0.6000 795ms - 25 seg | -0.5630 4692ms - 25 seg |
| hi (Hindi) | -0.3107 1425ms - 19 seg | -0.3489 743ms - 22 seg | -0.2503 4442ms - 22 seg |
| vi (Vietnamese) | -0.4714 1124ms - 17 seg | -0.5198 585ms - 20 seg | -0.4898 4766ms - 20 seg |
| ko (Korean) | -0.5908 1583ms - 24 seg | -0.6157 1183ms - 25 seg | -0.5541 4316ms - 24 seg |
| tr (Turkish) | -0.5138 1442ms - 15 seg | -0.4866 1096ms - 19 seg | -0.4769 5144ms - 19 seg |
| fr (French) | -0.7363 1316ms - 6 seg | -0.6186 1100ms - 8 seg | -0.5516 13233ms - 8 seg |
| de (German) | -0.1751 955ms - 4 seg | -0.2135 665ms - 6 seg | -0.2205 6068ms - 6 seg |
| it (Italian) | -0.6072 1708ms - 12 seg | -0.6149 950ms - 14 seg | -0.5672 8274ms - 14 seg |
| ar (Arabic) | -0.4274 1305ms - 47 seg | -0.4779 606ms - 51 seg | -0.4525 3282ms - 51 seg |
| nl (Dutch) | -0.2919 1563ms - 20 seg | -0.3477 565ms - 22 seg | -0.4110 3960ms - 22 seg |
| zh (Chinese) | No data | -0.3471 1834ms - 18 seg | -0.1618 12430ms - 18 seg |
Recommendations
For highest translation quality
Use Llama Maverick 4 - It won 10 out of 15 languages on COMET-QE, producing the highest overall quality score (-0.4481). It handles noisy ASR input well and had the lowest error rate (0.3% - a single timeout). The trade-off is speed: at ~6,088ms average it's ~7x slower than DeepL.
For real-time or high-volume translation
Use DeepL - At ~851ms average and ~1341 chars/sec, it's the fastest by a significant margin. Translation quality (-0.4863) is competitive with Google Translate and only slightly behind Llama. The official API is reliable and well-documented. Note: the free tier is limited to 500K chars/month.
For cost-sensitive batch processing
Use Google Translate (with the official API) - While this benchmark used the unofficial googletrans library (which caused all 52 Google errors), the official Google Cloud Translation API is production-grade. Quality (-0.4813) is competitive with DeepL, and Google won 5 out of 15 languages (Arabic, German, Dutch, Russian, Vietnamese). At scale, Google's pricing may be the most competitive.
Important caveats
Language coverage and speed warning: The 15 languages tested here (Spanish, Portuguese, Russian, Japanese, Indonesian, Hindi, Vietnamese, Korean, Turkish, French, German, Italian, Arabic, Dutch, Chinese) are among the most widely spoken languages in the world, with large amounts of training data available for all models. The broader corpus contains 180 languages , including many low-resource languages with limited training data (e.g., Kinyarwanda, Lao, Khmer, Amharic, Kyrgyz). While Llama Maverick 4 performed best on these common languages (10/15 wins), it should not be assumed it will maintain this advantage on rarer languages where Google Translate and DeepL - which have been specifically optimized for broad multilingual coverage - may hold an edge. Additionally, Llama's average latency of ~6,088ms per segment (with peaks reaching 64 seconds for longer texts) makes it impractical for real-time or high-throughput production use cases - it is roughly 7x slower than DeepL and ~5x slower than Google Translate. A follow-up benchmark on low-resource languages is recommended before making a final decision for the full language set.
- This benchmark used ASR transcripts - results may differ for clean, edited text
- Google Translate results are affected by the unreliable googletrans library; the official API would likely perform better
- COMET-QE is a model-based metric, not a human evaluation - scores are relative indicators, not absolute measures of quality
- Llama's higher length ratio (1.64x) means it produces more verbose translations, which may or may not be desirable depending on use case
- All three services were free at this volume; cost becomes a factor at scale
Translation Model Benchmark for Multilingual Video Transcripts - Generated from 293 segments across 15 languages (~500K characters)
Models: Google Translate - DeepL - Llama Maverick 4 (via Together AI) - Quality metric: COMET-QE (wmt20-comet-qe-da)